Today we’re releasing Let Me Get That Data For You (LMGTDFY), a free, open source tool that quickly and automatically creates a machine-readable inventory of all the data files found on a given website.
When government agencies create an open data repository, they need to start by inventorying the data that the agency is already publishing on their website. This is a laborious process. It means searching their own site with a query like this:
site:example.gov filetype:csv OR filetype:xls OR filetype:json
Then they have to read through all of the results, download all of the files, and create a spreadsheet that they can load into their repository. It’s a lot of work, and as a result it too often goes undone, resulting in a data repository that doesn’t actually contain all of that government‘s data.
Realizing that this was a common problem, we hired Silicon Valley Software Group to create a tool to automate the inventorying process. We worked with Dan Schultz and Ted Han, who created a system built on Django and Celery, using Microsoft’s great Bing Search API as its data source. The result is a free, installable tool, which produces a CSV file that lists all CSV, XML, JSON, XLS, XLSX, XML, and Shapefiles found on a given domain name.
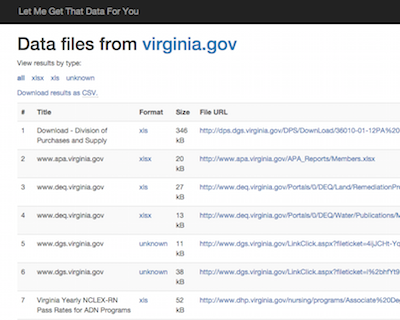
We use this tool to power our new Let Me Get That Data For You website. We’re trying to keep our site within Bing’s free usage tier, so we’re limiting results to 300 datasets per site. At the moment, for demonstration purposes, we’re permitting searches of .gov, .com, .net, and .org sites, but we’ll reduce that to only government domain names in a few days—again, just to minimize our own API costs.
You’re welcome to try it out! Pull requests and issues are welcome, of course.